python3爬虫入门之二Urllib的高阶用法
流水
9月 13, 2017
请求头部信息
有的网站会对请求的信息进行检测,以此来屏蔽掉非法来源的请求信息,为了欺骗服务端,我们需要伪造一些信息,
我们先来看一下访问知乎的时候,浏览器的发送的请求头是什么
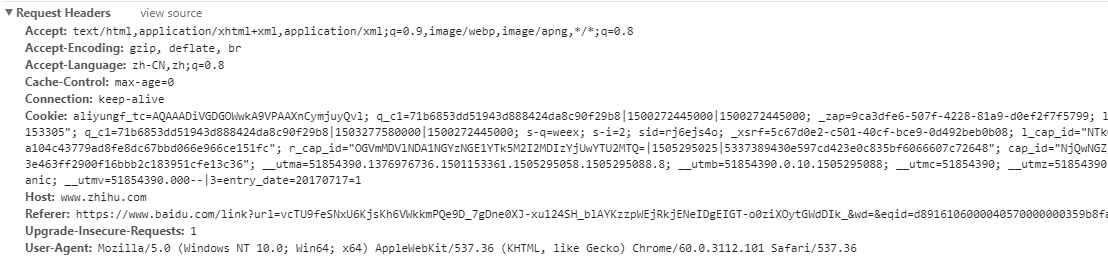
通过观看这个请求,发现浏览器会向服务端发送好多内容
User-Agent: 浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用Content-type: 接受类型,通常是使用接口请求的时候,服务端返回的类型Cookie: 最重要的请求信息之一, 会携带服务端需要的数据信息Referer: 包含一个url,是请求发出的页面的urlHost: 初始主机的url和端口
因此当我们写爬虫的时候,有的时候需要模仿这些信息
|
|
通过模仿来源,让服务端认为是自己人,成功的引狼入室